日常生活中,當我們在用搜尋引擎查詢時應該都經常受一個功能的輔助:
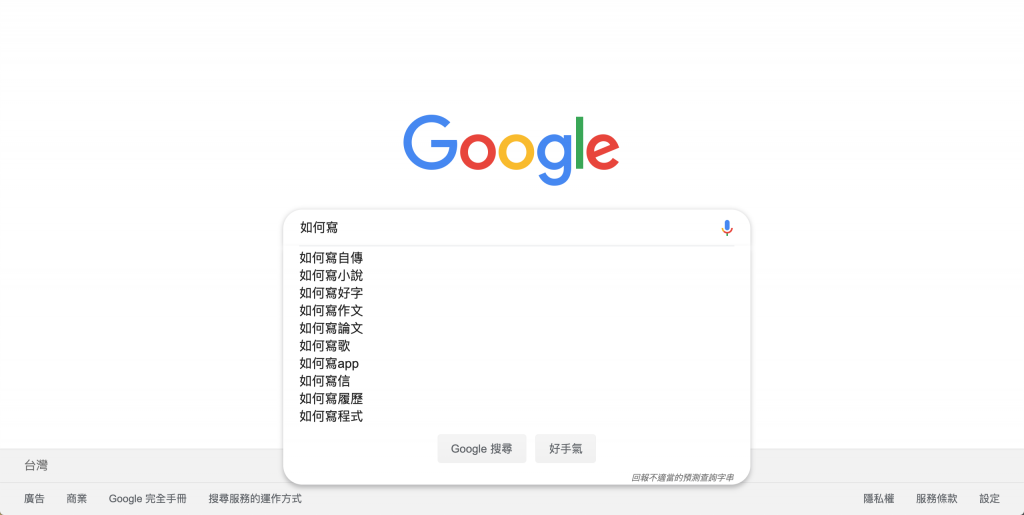
預測查詢,或稱為完成查詢,顧名思義,這功能用於輔助使用者完成他們的查詢。
完成查詢除了能輔助使用者完成他們的查詢詞句之外,還有以下幾個好處:
在進行完成查詢時,當輸入完一個片段的查詢字串之後,通常會用以下的演算法:
那麼,這個候選清單又是怎麼來的呢?候選清單常來自於使用者過去的搜尋紀錄、時事話題、以及該字串歷史紀錄中的常見查詢結果。
而為了讓預測查詢能夠在有效率的狀態下進行,我們會使用Trie+範圍最值查詢演算法。這邊有一個Trie演算法視覺化的網站,可以玩玩看。
接著來說說擴展查詢。使用者和檔案有時會用不同的字詞來表達同一個意思,例如,禮拜天和星期日,明明都是指同一天,但卻用了截然不同的三個字。這樣的錯位會影響到搜尋結果的召回率(Recall),而使用者自己也常需要手動的修正這類型的錯誤(像是換些字重查)。
為了解決這類型的問題,我們首先會用兩種方式解決:
(1) 儲存同義字、相似字
(2) Word2Vec,從大量文集中搜集資料,知道哪些字在語言中處於相似的地位。假設我們有兩句話,「禮拜天是休息的日子」以及「星期日是休息日」,那麼在Word2Vec的向量當中就會認為這兩個字是相似的。
除此之外,我們還會用三種相關性回饋(也稱為相關反饋)來解決這些問題:
(1) 顯式反饋:搜尋引擎可能會問你,這個頁面對你(的查詢)有沒有幫助。
(2) 隱式反饋:透過像是Google Analysis的功能,分析你有沒有點進這個頁面,以及你在這個頁面待的時間有多久(點進去不到十秒就跳出來說明這頁面可能不是你在找的)。
(3) 盲式反饋:搜尋引擎會在在搜尋結果的幾個頁面中找可能是相關字的字(尋找一個議題時,幾個類似的字可能反覆出現在這幾頁面中,說明這幾個字有可能有關聯)。


 iThome鐵人賽
iThome鐵人賽